The trend toward wrapping together data and security filtering into RESTful web services has only increased in the past few years, and for a lot of good reasons. If the REST API is optimized to return very quickly based on a set of filtering parameters, the performance alone can justify the architecture. However, Tableau is planning to do more with the result set than simply display it directly — Tableau is ready to do deep analysis and discover new insights. Because of this, Tableau’s VizQL engine needs something it can query in many different ways as the basis for a data source connection.
How can we bridge the gap between a JSON (or XML, if anyone still does that) object response and a relational query engine?
What if I told you THIS was all that was necessary on the Tableau Desktop side to build a data source that acts as a “live” connection to a web service?:
Accessing the PL/Python Function in Tableau
Connect to the PostgreSQL database in Tableau Desktop using whatever credentials you created for an end user.
Then on the Data Connection screen, you’ll find on New Custom SQL on the left:
If you drag that out, then the dialog to define the Custom SQL query appears:
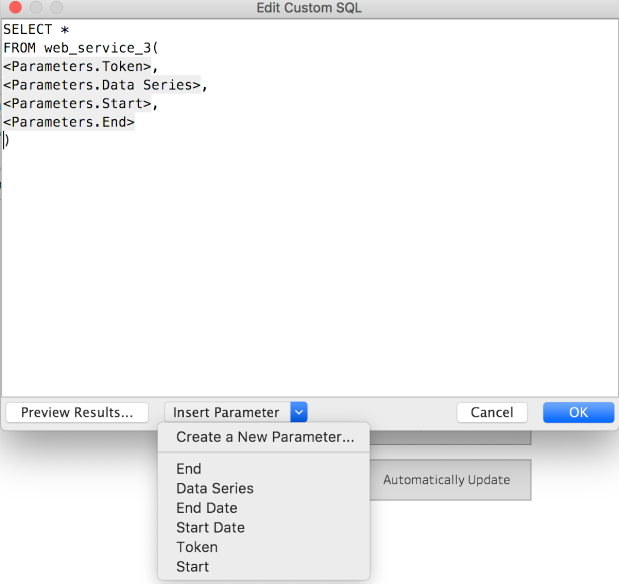
As you can see, the query is just SELECT * FROM function_name( arguments ), with whatever parameters you want to attach. You can create new parameters right from this dialog box, then put them in place. Make sure to give sensible defaults, and probably most should default to an empty string so that someone can only access if they have the right tokens / etc.
How is this possible?
There’s a whole lot of setup on the PostgreSQL side, but the payoff is the simplicity of the setup in Tableau.
The solution is based on the architecture originally laid out here, but I’ve put together a Dockerfile which builds out a PostgreSQL database ready for your custom set of functions which will dynamically call a RESTful Web Service based on Tableau’s parameters.