This documentation is for versions of Tableau prior to 2018.3. What are you doing here? You’ll want to implement Row Level Security using Multi-Table Extracts and the “Standard” Method of Row Level Security. Read all about them at:
How to set up your Database for Row Level Security in Tableau
Quick Explanation of Row Level Security in Tableau
If you are on a version prior to 2018.3, please turn around and plan an upgrade path
Matt Miller works at Tableau as a sales engineer along with Bryant. He’s guest posting this excellent set of articles, with hopefully more to come.
Note: This and Part 2 document some older techniques for achieving RLS in a much more limited version of Tableau that existed in the past. If you made it past the red text above, should follow their instructions. If you are just here for fun, skip right to Part 2, then come follow the instructions above in red.
A wise man who runs a well-respected Tableau blog once wrote:
“To be secure and perform well, you must use a Live Connection to your database. Extracts will be too large if you join a security table that is one-to-many to your data table (we say they “blow up” to dissuade people).”
What happens when a live connection is less than desirable for a use case, or downright impossible? Are we to let our Tableau Server users swim in a sea of insecure extracts (‘Do my columns look wide in this?’) ? Certainly not. The methods used to secure extracts differ from most currently published Row Level Security setups or walk-throughs, as the design is centered around minimizing duplication of rows to ensure performance in both creating and using them.
Since my education in uncountable infinite sets ended in undergrad, this blog won’t try to cover every niche business logic and data security use case, but instead provide ideas and tools to take back you your own environment and mold to your needs.
Tableau of Contents
- What Causes Extracts to “Blow Up”?
- Glossary of Terms
- Solutions
- 1-to-1 Relationship – One Row Belongs to One Person
- 1-to-Group Relationship
- Multiple Groups
- 1-to-Groups Relationship
A brief note before we jump into the fray, but these methods were tested using Tableau 9.3. Tableau 10 introduces groundbreaking features including cross-database joins, which open up new opportunities and possibilities to use the extract engine for the row level security use case. We’re currently testing different scenarios to see where we can add flexibility and start using solutions more akin to the current live connection best practices in How to Set Up Your Database for Row Level Security.
What Causes Extracts to “Blow Up”?
Let’s take a tried and true Tableau example to introduce the concept of joining to a security table and implementing row level security in Tableau, then see what happens when we take things one step further:
In this example each of our Regional Directors are tied to their region in a pared down security table. When we join to the table/view/data set that we wish to secure, each row that contains a manager’s region will now contain a column that holds their name.
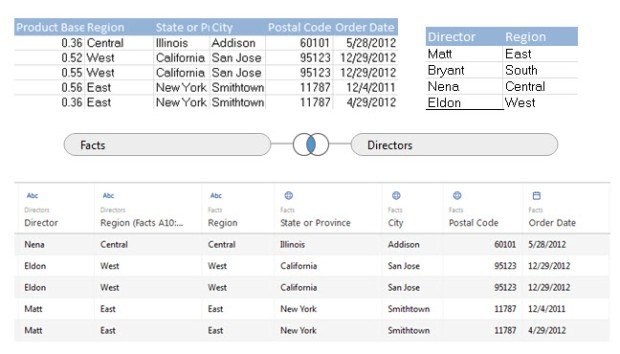
Row level security is implemented with a simple Boolean check comparing a user’s Tableau Server user name to their name in the newly created column. Filter down to all my ‘True’ values, and your father has a brother named Robert.
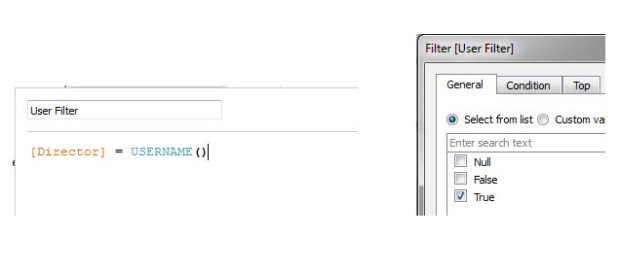
I’ve shown this example to countless customers in order for them to understand the basics of programmatic row level security within Tableau, and roughly a quarter of those times, someone comes back with something along these lines:
“Wow, that’s excellent that you can build the security in right from Desktop, but what happens when I have 10 people that need access to each region? Or what happens when we need Regional security for our Directors, and then State level security for our Managers underneath that? Do we really need to have a row duplicated for EVERY individual user name that needs to access it?”
With a live database connection, the database should be able to look at this situation logically and not actually build a combined table with all of those combinations, which is why the live connection version of row level security is the one that we often recommend.
But when talking about extracts, fielding that question was a nightmare, because a Tableau extract always creates those extra rows, both in the database and then in the extract itself. Finally, I had to swallow the hard truth. If you want to use the USERNAME() calculation, then yes, yes you do need to do the joins, you do need to create the entire combined table, and this is what causes your extract to blow up. Creating that one-to-many join is what will duplicate data and possibly destroy extract creation time and/or performance.
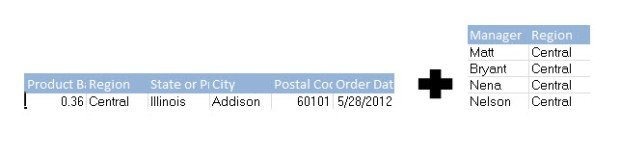
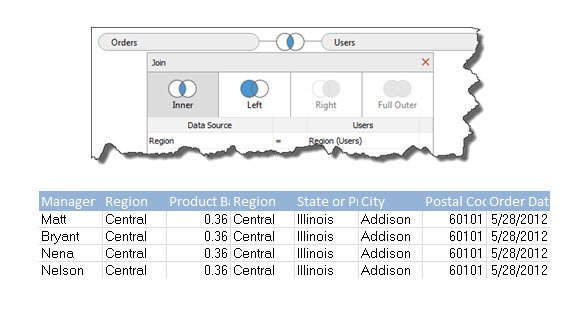
An example having regions with 15 users each, multiplied across N rows for each region and we’re looking at a 15*N duplication of our data for every region and therefore the entire dataset. The example here is a simple one, but you can imagine a scenario where someone with an external facing dashboard needs to secure an extract for hundreds or thousands of customers. Imagine your refresh time and performance now, and then imagine it against a data set that’s been increased by a factor of 500-1000, not a pretty picture for most.
So how do we maintain this security without duplicating the data? There are a few common scenarios I’ve seen that I’ll cover here which can be built upon to cover more advanced security cases, or have a programmatic element built in so that the manual upkeep of the security is minimized.
Glossary of Terms
Before we go further, let me clarify on the terms I’ll be using.
Granularity – Granularity, or the grain of the data, is the depth or level at which data is defined or aggregated. A dataset that is aggregated to or defined at a regional level would be a coarse grain, or not very deeply defined. Whereas a dataset that aggregates to the state level would be finer grain than that, or be more deeply defined, since States aggregate up to Regions. The grain of data is important to Row Level Security because different users may have different levels of access depending on how finely we define our data for different dimensions or attributes.
Row Duplication – Row duplication in a dataset is exactly as it sounds, a specific row being duplicated due to a join to another table. In the case of Row Level Security, we’ll see row duplication occur when we want to give multiple users access to a single row of data. The join would cause the initial row to be duplicated for as many users that need access to the data.
Blowing Up - When we say an extract ‘blows up’, we mean that rows of data have been duplicated to a high degree due to a one-to-many join, many times unnecessarily in an attempt to secure the extract at the row level. The size of the extract increases to an untenable size leading to undesirable performance and extract refresh times.
Keys – In a database, a key is a column with values that match up between two tables or objects. A Region column in a fact data set might match up with a Region column in a security table, matching on the ‘Key Values’ like East, West, etc. to combine the appropriate data from both tables/sets. A ‘Primary Key’ in a table is a column that contains unique values for each row with no null values, something like an ID field is normally defined as a Primary Key.
Solutions for Situations
1-to-1 Relationship – One Row Belongs to One Person
This is the scenario that was covered in the first example:
If each row of data will only be accessed by ONE person, and the username which matches Tableau can be joined to the table, there’s no difference in the resulting data set whether using a live connection or an extract. This is evident because after we create the join, there’s the same amount of rows in our resulting set as there was originally. Again, this is a basic setup that’s inapplicable to most use cases because of more advanced security needs. The security calculation in Tableau will again be:
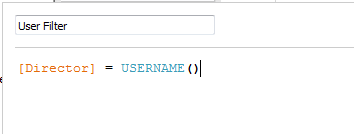
1-to-Group Relationship
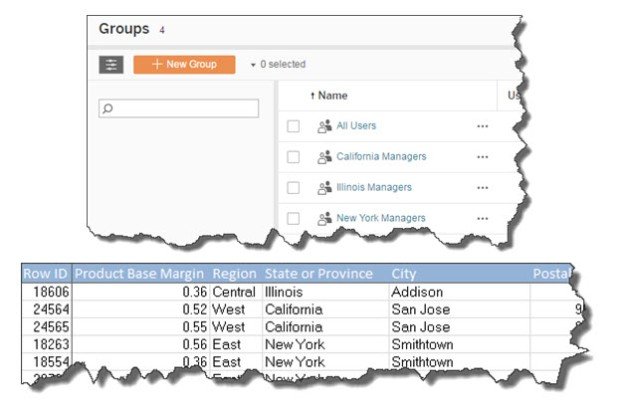
In the simplest case, each row of data only has one Group who has access to that row, regardless of how many users are in that group. For example, all California managers may have access to every row containing California. This is the case that we’ll call a 1-to-Group relationship
As we saw earlier, if we join the usernames, the extract will blow up. Instead attaching each person’s username to each row of data, we only need a way to filter based on those groups. You do not need the Group names themselves to be in the data; if you know the values of a field that a given group can see, you can define that directly in the Tableau calculations.
For example, if we have multiple managers per State that are going to access an extract, then hopefully there should be some field containing state values in each row of the data set.
To build a Row Level Security calculation in Tableau, we’ll use the ISMEMBEROF(‘Group Name’) function. You must pass the actual string value of a Group name into ISMEMBEROF(), and it will return a Boolean that will return True when the signed in user belongs to the specified group. Using ELSEIF, you will make a statement for every Group, then define the comparison to the data in a second IF clause, as follows:
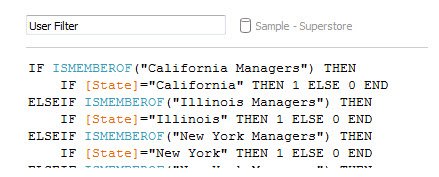
You can extrapolate that those secondary security clauses under each group clause can be more complex than just checking one particular field; you can use AND, OR, or even nested IF clauses for very specific effects.
While the calculation may end up long, this method solves the problem of “blowing up” the rows, and is actually simpler than standard row level security from a data perspective, as it requires no joins to a security table. The upkeep here is in making sure people are in the correct Tableau Server groups (automatable with the REST API or tabcmd) and maintaining the new calculation that will now secure the extract.
Multiple Groups
What if I have two fields that define access? For example, a manager might have a State allocated, but also a particular line of business.

Users can belong to multiple groups in Tableau Server, so in our example, a user might be put into the Illinois group and the Technology group. In effect, you’d have different “classes” of Groups – “State” groups and “Category” groups.
You can create two calculations, one for the State groups and one for the Category groups, and Tableau will evaluate both of them, so that a user only sees their specific State and Category.
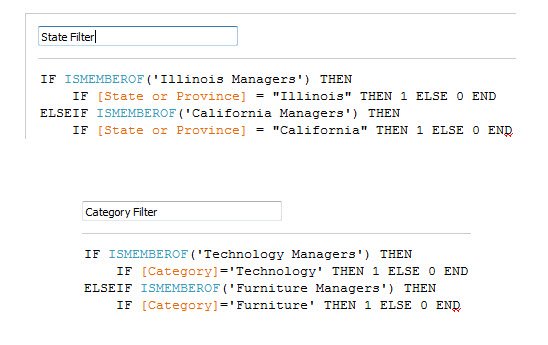
Alternatively, you can build the logic to check both classes of groups into a single larger master calculation, then something like a group of “Illinois Technology Managers”.
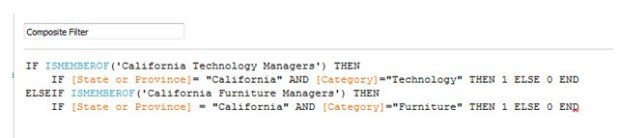
Let’s take a quick example from this use case to explain Tableau’s logic here. Justin from our small sample of data logs in to Tableau Server and opens a dashboard that uses this particular extract. The logic here will look for Justin’s group that he belongs to on Tableau Server. Justin’s row of data denotes that he is a California Furniture Manager, and I’ve set up my Server groups to have that name as well. Only after the initial condition of belonging to a specific group is met will we move on to the nested IF statements that proceed from them. In Justin’s case, after we recognize his membership of California Furniture Managers, the logic simply says that if the row of data we’re looking at has California as its State and Furniture as its Category then we’ll assign it a 1. Think of the non-indented statements as finding out which group someone is in, and the indented statements that follow will then define the data that the specific group can access. Tableau goes through this logic on-the-fly and programmatically based on whoever is accessing the data.
Pros
The clear benefit is the non-duplication of the rows in our extract and only dealing with the datasources that you’re used to without having to worry about accessing and adding in your security tables.
Cons
The drawbacks are that a new, more hardcoded calculation needs to be maintained to reference our Server Groups and said groups must also be created and maintained. While the calculation might seem arduous, the initial build is usually a litany of Ctrl-V’ing and inputting the correct values for the correct groups.
You can’t use a field name in ISMEMBEROF, because it is calculated before Tableau queries the data source (to allow for optimization). This necessitates a longer calculation that will explicitly define each group name and their corresponding security clauses.
Making It Easier
Since the calculation itself is very templated, perhaps building a simple JS app where you can input or import group names from the REST API and then compare it to values that are either input or imported from the database can be a more end to end, fully integrated solution. Measuring the time and effort of your team maintaining this type of group security against the time and effort of your database and the Tableau Data Engine during duplication is a good way to begin thinking about which route would be more beneficial for your deployment.
1-to-Groups Relationship
The other case is where we’ll have several groups with the permission to access one row. Think of an example like earlier where the Central Director and all Texas State Managers will have access to the same row of data while belonging different groups. This is what we’ll define as a 1-to-Groups relationship.
Even the previous 1-to-Group relationship type is more simplified than the business logic and security rules that we see customers wanting to implement in the real world. Normally, there will be varying layers of access depending on multiple attributes or roles. Companies can house these hierarchies in many different manners, but for use in Tableau, the best way to think about hierarchical security is with a ‘flattened out’ version of the security table where users roles and attributes that will define what they have access to in the desired extract. We won’t be joining onto the table for this example, but it does a good job of defining our thought process as we begin to write logic against the extract.
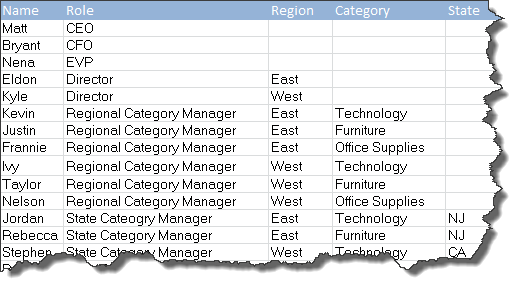
Again, unlikely that anyone’s security tables are this clean, but perhaps we’ve put together a nice pared down view of our tables in order to see who should have access to what. There’s a clear cascade here, from our C-Level suite, down to State Category managers who oversee, you guessed it, a specific state and category. In this case, there’s only one person at each level of our hierarchy, so it might seem like the following calculation is an arduous task, but again, there could be ten or twenty users at each level.
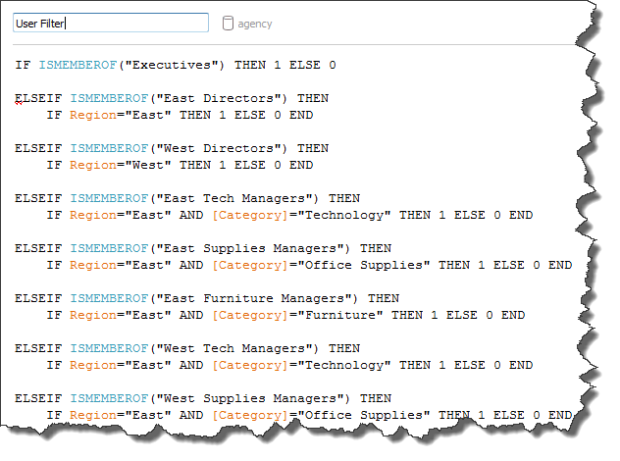
Definitely another use for a small application that is more automated than my or a developer’s CTRL-V acumen. For what it’s worth, it took me less one minute to write the resulting calculation, so while not ideal for thousands of groups, it’s a good starting point for those looking to start implementing security into your extracts. Certainly preferable to not allowing your users access to a datasource they’ve been clamoring for or having your blown up extract (that production workbooks depend on) refreshing from Friday afternoon until Monday morning.
The solutions offered here are all ones that have been implemented in part or in whole by Tableau customers. They will certainly work, and work well, but they still beg the question: “Is there a way we can make this automatic without having to maintain verbose and specific logic calculations?” In between shakes of my fist at the functionality of ISMEMBEROF(), I’ve tracked down real world solutions that are used by our customers and Tableau Solution Architects internally in order to achieve such an outcome.
Read on to Part 2 for full production level solutions!

This is a great post and nicely summarizes a lot of the thought processes we went through when figuring out how to secure our TDEs for a recent project. As you mention, these approaches may not work too well for very large data sets but they work very well (in our experience) for data sets under 10M rows. I look forward to part 2.
Here’s a write-up of the approach we took:
http://mixpixviz.blogspot.com/2016/03/row-level-security-on-published-tableau.html
LikeLike
Thanks, Michael! Part two is posted with a solution based on your blog under Hybrid Solution. Your post was the inspiration for the extensive write-up, so many thanks in helping to add to everyone’s security repertoire.
LikeLiked by 1 person
I just read Part 2….thanks for the nod. 🙂 The CONTAINS option is very intriguing…I will want to give that a try since we’re being asked to add a few hundred new users at a fairly granular level. This might be a good way to avoid blow up.
LikeLike