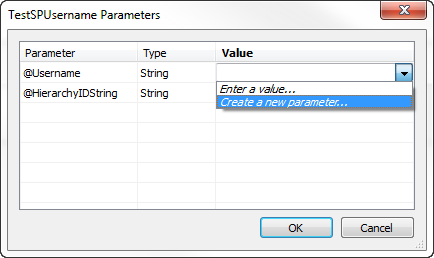
You’re probably aware that Tableau Parameters are not an inherently secure way to filter down data. A lot of people are using JWTs to pass around tokens with security entitlements, so if you are good with that, did you know you can pass one right into a Tableau Parameter?
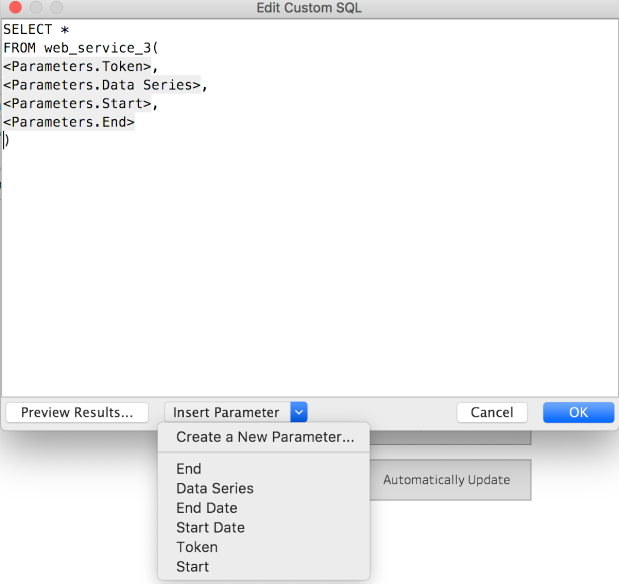
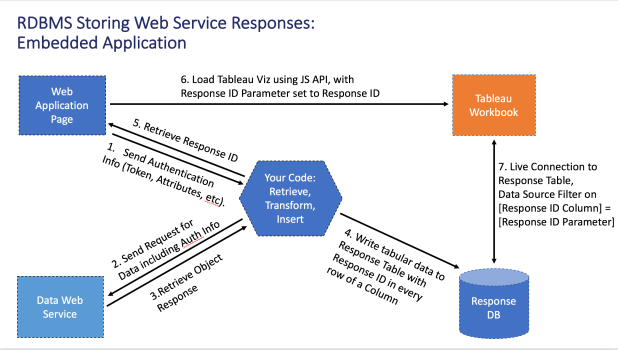
I’ve built out an example where the JWT comes through then a function fires off a web service request, as part of the work for using a Web Service / REST API as a live data source, but there’s no reason you couldn’t build a smaller function for processing the JWT and then use just that in Custom SQL in Tableau when building your data source.
Although the following example uses PostgreSQL (and PL/Python), you could theoretically implement this in any language with access to a language that can process JWT. In MS SQL Server, a CLR Stored Procedure can access C# functionality, and the Systems.IdentityModel.Tokens.Jwt namespace appears to have all the necessary functionality to implement a very similar workflow.
Below I’ll work through a workflow using PL/Python on PostgreSQL — again, the same concept could be implemented on any RDBMS with functions.